Major Amazon Web Services Outage Disrupting Global Internet Services UPDATE5

Connectivity to many popular internet services and systems across the world, such as Alexa, Snapchat, Fortnite, Signal, Perplexity, Slack, HMRC, Roblox, Ring and many more (payment providers, VoIP services etc.), are being disrupted this morning after cloud-platform Amazon Web Services (AWS) appeared to suffer a major global outage.
According to Ookla’s Downdetector service, the disruption appears to have started just after 7:44am, although in the past few minutes the situation has started to improve. AWS currently says that its engineers have applied “initial mitigations” and “are observing early signs of recovery” for at least some affected services.
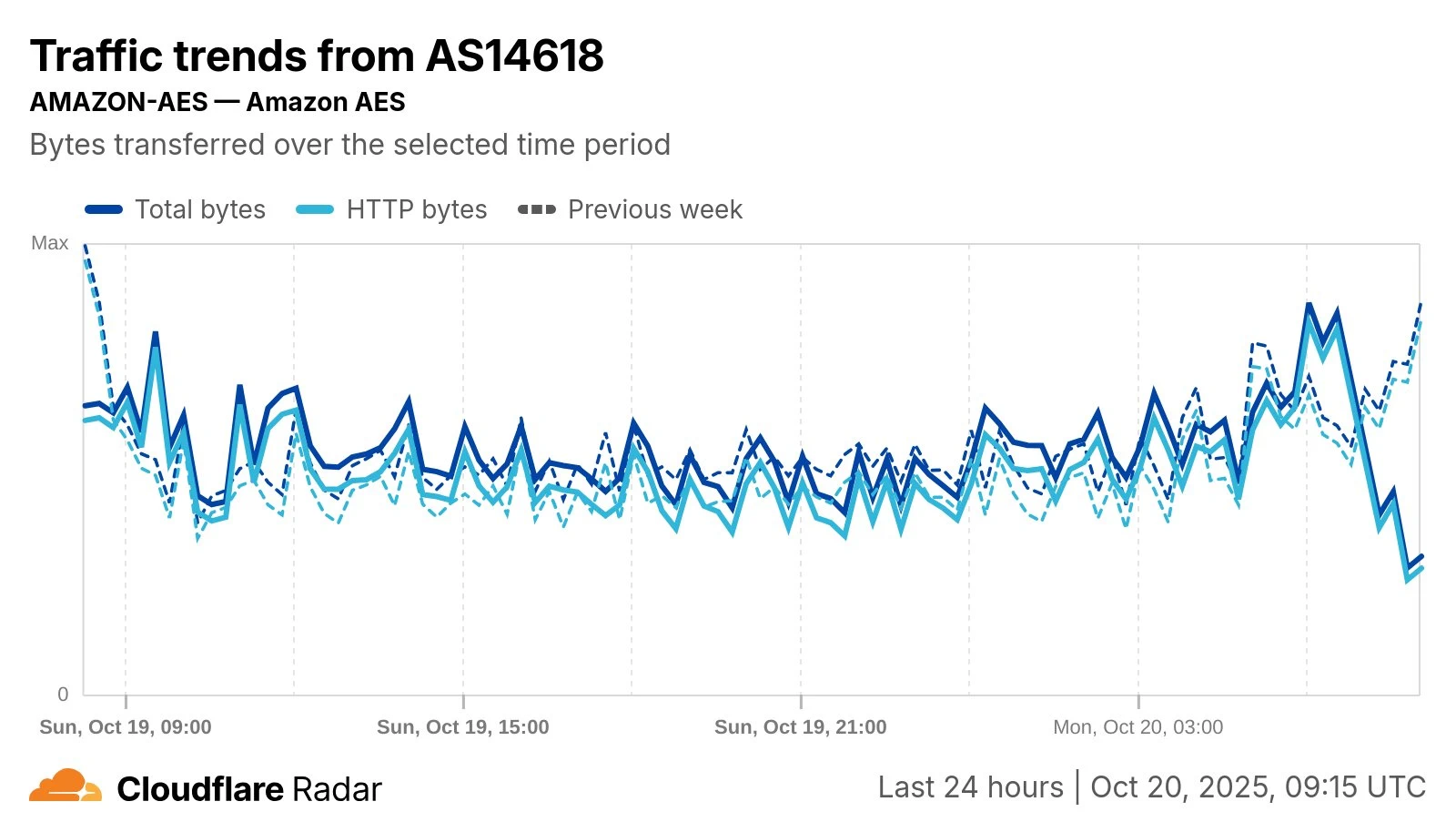
Meanwhile, Cloudflare’s data shows a clear drop in AS14618, associated with AWS’s US-East-1 region (Ashburn, Virginia) — one of AWS’s largest and busiest data centre regions — starting around 8am UK time. Traffic fell by as much as 68% at 9am UK time.
Advertisement
Some of the services impacted include Amazon itself (partial), Amazon Alexa, Amazon Music, Amazon Prime Video, Amazon Web Services, Ancestry, Asana, Atlassian, Bank of Scotland, Blink Security, BT, Canva, Clash Of Clans, Clash Royale, Coinbase, Dead By Daylight, Duolingo, EE, Epic Games Store, Eventbrite, Flickr, Fortnite, Halifax, Hay Day, HMRC, IMDB, Jira, Life360, Lloyds Bank, My Fitness Pal, Peloton, Perplexity AI, Playstation Network, Pokemon Go, Ring, Roblox, Rocket League, Signal, Sky, Slack, Smartsheet, Snapchat, Square, Tidal, Whatsapp, Wordle, Xero, Zoom and more.
UPDATE 10:46am
AWS are now reporting signs of recovery. “We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests. We will continue to provide additional information,” said the company.
Advertisement
Summary of AWS Service Status Updates
Increased Error Rates and LatenciesOct 20 2:27 AM PDT We are seeing significant signs of recovery. Most requests should now be succeeding. We continue to work through a backlog of queued requests. We will continue to provide additional information.Oct 20 2:22 AM PDT We have applied initial mitigations and we are observing early signs of recovery for some impacted AWS Services. During this time, requests may continue to fail as we work toward full resolution. We recommend customers retry failed requests. While requests begin succeeding, there may be additional latency and some services will have a backlog of work to work through, which may take additional time to fully process. We will continue to provide updates as we have more information to share, or by 3:15 AM.Oct 20 2:01 AM PDT We have identified a potential root cause for error rates for the DynamoDB APIs in the US-EAST-1 Region. Based on our investigation, the issue appears to be related to DNS resolution of the DynamoDB API endpoint in US-EAST-1. We are working on multiple parallel paths to accelerate recovery. This issue also affects other AWS Services in the US-EAST-1 Region. Global services or features that rely on US-EAST-1 endpoints such as IAM updates and DynamoDB Global tables may also be experiencing issues. During this time, customers may be unable to create or update Support Cases. We recommend customers continue to retry any failed requests. We will continue to provide updates as we have more information to share, or by 2:45 AM.Oct 20 1:26 AM PDT We can confirm significant error rates for requests made to the DynamoDB endpoint in the US-EAST-1 Region. This issue also affects other AWS Services in the US-EAST-1 Region as well. During this time, customers may be unable to create or update Support Cases. Engineers were immediately engaged and are actively working on both mitigating the issue, and fully understanding the root cause. We will continue to provide updates as we have more information to share, or by 2:00 AM.Oct 20 12:51 AM PDT We can confirm increased error rates and latencies for multiple AWS Services in the US-EAST-1 Region. This issue may also be affecting Case Creation through the AWS Support Center or the Support API. We are actively engaged and working to both mitigate the issue and understand root cause. We will provide an update in 45 minutes, or sooner if we have additional information to share.Oct 20 12:11 AM PDT We are investigating increased error rates and latencies for multiple AWS services in the US-EAST-1 Region. We will provide another update in the next 30-45 minutes.
UPDATE 11:34am
Despite AWS slowly getting back to normal, people are still reporting problems with various linked services, such as Ring. It may take time for everything to fully return. A number of broadband ISPs, such as YouFibre, appear to have support (phone, chat etc.) systems that depend upon AWS and have been disrupted. Sky Broadband are also reporting phone problems, although it’s unclear if they’re AWS related.
UPDATE 4:21pm
Plenty of internet services are continuing to experience problems. The latest update from AWS is as follows:
Advertisement
AWS Update – Oct 20 8:04 AM PDT
We continue to investigate the root cause for the network connectivity issues that are impacting AWS services such as DynamoDB, SQS, and Amazon Connect in the US-EAST-1 Region. We have identified that the issue originated from within the EC2 internal network. We continue to investigate and identify mitigations.
UPDATE 4:37pm
The latest update from Cloudflare confirms ongoing issues for some: “Despite traffic from AWS AS14618 returning closer to normal levels, Cloudflare data still shows signs of degraded performance and elevated local HTTP 5xx errors, indicating more failures than usual.”





Mark is a professional technology writer, IT consultant and computer engineer from Dorset (England), he also founded ISPreview in 1999 and enjoys analysing the latest telecoms and broadband developments. Find me on X (Twitter), Mastodon, Facebook, BlueSky, Threads.net and Linkedin.











« Broadband ISP Virgin Media UK Sees 285 Percent Rise in Phishing Threats


























Something this once again highlights is the “flimsiness” of smart devices requiring an internet connection. How many people woke up this morning and were unable to turn on lights, or do other things they normally do with Alexa? What if services for other devices go down?
There will of course be some who solve this with solutions like Home Assistant and Zigbee2Mqtt and other such things, but a discussion needs to be had about making smart devices local-first, internet-second to avoid a situation where you can’t ring a doorbell because a datacentre in the US suddenly fell over.
That is why you have a back-up, I use Philips Hue for lights and remote switches, so even with no internet, as long as the hub is powered on, I can still turn lights on and off. It explains why Alexa was being a bit slow.
I have one with wifi and bluetooth – don’t even need the hub on it’s great and they were very cheap
More and more providers (netatmo, and recently tado) preventing access to your data, locally.
There is no Plan B, data is lost, heating requires manual intervention, ok for the able, not so good for the disabled.
Data is being stolen, monitoriesed and for other purposes.
All credit to those who can get at the data locally and share their research
I use Home Assistant and make sure that everything I buy to connect to it only requires local access for full functionality.
There is absolutely no reason for home automation services to be connected to data-centers in the US except that corporations like Amazon and Alphabet want to monitor and monetize your every action.
I have recently pre-ordered a new small box with Home Assistant pre installed and it also has an optional simpler interface too. Getting it so my devices still work when the internet goes down.
Such a shame when you can’t use a light switch , these cave man manual processes were so much more reliable weren’t they
@Disgruntled of Dankshire, what data does Tado have, apart from address if you use their geofencing , email and payment card if you subscribe?
I don’t know how Tado would work without the internet, I presume like my old system it would just work, but without app support.
I may try it tomorrow if I remember
@JimB, I keep going to have a muck around with Home assistant, I have it installed on a Dell thin client, but getting the time to go thorough it and learn it. I get so far and then lose concentration. Would be useful as I have stuff that don’t talk to each other, home assistant would change that
It’s a GET OFF THE INTERNET day lol. Courtesy of AWS. The amount of traffic that must go through AWS servers must be nuts. Hopefully it’s not the Russians or Chinese or chancer hacking groups after some bitcoin.
We’re back to the “It was DNS” cartoon. What’s interesting is how this highlights our vast dependency on the small number of US cloud titans. Swathes of UK government bodies, companies large and small, and all kinds of our infrastructure depends on AWS. Despite it being ‘ultra-resilient’ with regional datacentres all around the world, there remain some non-regionalised core services that seem critically dependent on that us-east-1 region, the ‘original’ and biggest AWS hub. No doubt there will be some busy meetings in AWS Towers this morning…
Why does HMRC depend on anything US based?
Surely they should only be using UK and EEA based hosting (available from Amazon, Microsoft, Oracle and many others). It would be possible to be sufficiently resilient solely with EEA based hosting.
Some services/integrations can only be done out of us-east-1 (or in some cases they used to be only available in us-east-1 but can be done elsewhere, but companies using it aren’t aware or don’t want to change something that is working). I expect this will nudge both AWS and those using it to check their options. So the core data is in the UK but it has to connect out to process something elsewhere.
I once had an account with StupidBank, which for some inexplicable reason built into their website a link to another site in Trumpostan.
Connection to Trumpostan went down, could not access my account.
Moved the money out of StupidBank.
As an aside I had to transfer lots of funds from StupidBank to another bank to buy something.
Asked StupidBank, after trying to send amounts gradually reducing to get the funds sent, what the daily limit was, to be told it varied and was Secret.
Luckily my other half found the limit on a site for most banks. What a farce.
Eggs in one basket always comes to mind!
Exactly , my words too
I was more annoyed at Rings service status still saying ‘this is fine’, spent some time this morning thinking it was my network that was the issue.
Get visitors to knock.
Ah, the Microsoft Azure approach to service status. “We’ll let the customers know it’s us once they’ve spent a couple of hours trying to fix it at their end.”
Amazon make a few quid from all the companies don’t they
Can’t imagine what the world will be like the day Jeff turns off his computer and goes and lives on another planet with Elon.
Much better.
Could not agree more with the Eggs in one Basket comment!
I Literally cannot wait for the Spitting Image Webisode to come out that I am sure will feature this monumental cockup
Many UK government departments use AWS, as well as worldwide. I read that’s where the get most of their profits. Scary if it’s been another country hack.
of course it’s Russia. The Mafia boss in America has allowed them to do it by stopping all the beneficial measures the NSA had in place.
It is a good job it did not happen when the F1 grand Prix was on, they use AWS for some stuff.
@Ad47uk
AFAIK tado gets data from all the thermostats etc. Thats how you get the email sayin the battery needs replacing.
From them was a useful level of the solar intensity.
All this is not available locally, but via their token controlled web server, which recently limited access to 100 attempts, but 20000? if you pay.
Fair enough, i can understand the cost to keep servers running, but for people like me who uses their own charts etc, it now has become very difficult.
Netatmo has a similar model, data is encrypted, but in the past it wasn’t. Now you have to go and get it, and imho their website is awful (mine are fabulous)
In a nut shell, no internet, no data, and no heat unless you do it manually
So beware, you may buy a device that you or HA can use, until they change the rules.
Also, I have my own ntp server using GPS, as in the past I had a bit of kit that would not boot if it could not get the time.
I think this incident just is a reminder that we need to step away from relying on the US all the time. Was completely unaffected yesterday (apart from an internet issue that was firewall related apparently), but we should not be relying on all this American infra
Exactly, the Internet (from arpanet) was designed for resilience, however the bits on the end it appears may not have sufficient reliability.
Typically firms don’t want to accept that a failure will seriously affect their bottom line, till it does.
Home routers with poor security.
Single connections, poor UPS’s, generators not tested etc etc
Poor management.